The more logs there are, the better. In actual development, we often encounter a lot of useless logs, but not the logs we need; or the valid logs are overwhelmed by a large number of useless logs, making them very difficult to find.
An excellent log package can help us better record, view and analyze logs, but how to record logs determines whether we can obtain useful information. The log package is a tool, and logging is the soul. Here, I will talk about how to record logs in detail.
Table of contents
Open Table of contents
Youtube Video

Where are the logs printed?
Logs are mainly used to locate problems, so generally speaking, we need to print logs where they are needed. So where are they specifically?
Print logs at branch statements. Printing logs at branch statements can help you determine which branch the code took, which helps you determine the next hop of the request and then continue troubleshooting.Write operations must print logs. Write operations are most likely to cause serious business failures. Printing logs for write operations can help you find key information when problems occur.Be careful when printing logs in a loop. If the number of loops is too large, a large number of logs will be printed, which will seriously affect the performance of the code. The recommended method is to record the key points in the loop and print them out outside the loop.Print the log at the original location where the error occurred. For nested Errors, the Error log can be printed at the original location where the Error was generated. If the upper layer does not need to add necessary information, it can directly return the Error of the lower layer. Let me give you an example:
package main
import (
"flag"
"fmt"
"github.com/golang/glog"
)
func main() {
flag.Parse()
defer glog.Flush()
if err := loadConfig(); err != nil {
glog.Error(err)
}
}
func loadConfig() error {
return decodeConfig() // return directly
}
func decodeConfig() error {
if err := readConfig(); err != nil {
return fmt.Errorf("could not decode configuration data for user %s: %v", "colin", err) // add some necessary information, such as username
}
return nil
}
func readConfig() error {
glog.Errorf("read: end of input.")
return fmt.Errorf("read: end of input")
}By printing the log at the location where the error was originally generated, we can easily trace the source of the log and then add some necessary information to the upper layer. This allows us to understand the impact of the error and helps troubleshoot. In addition, directly returning to the lower layer log can also reduce repeated log printing.
When the code calls a function of a third-party package and an error occurs in the third-party package function, an error message will be printed. For example:
if err := os.Chdir("/root"); err != nil {
log.Errorf("change dir failed: %v", err)
}At which log level are the logs printed?
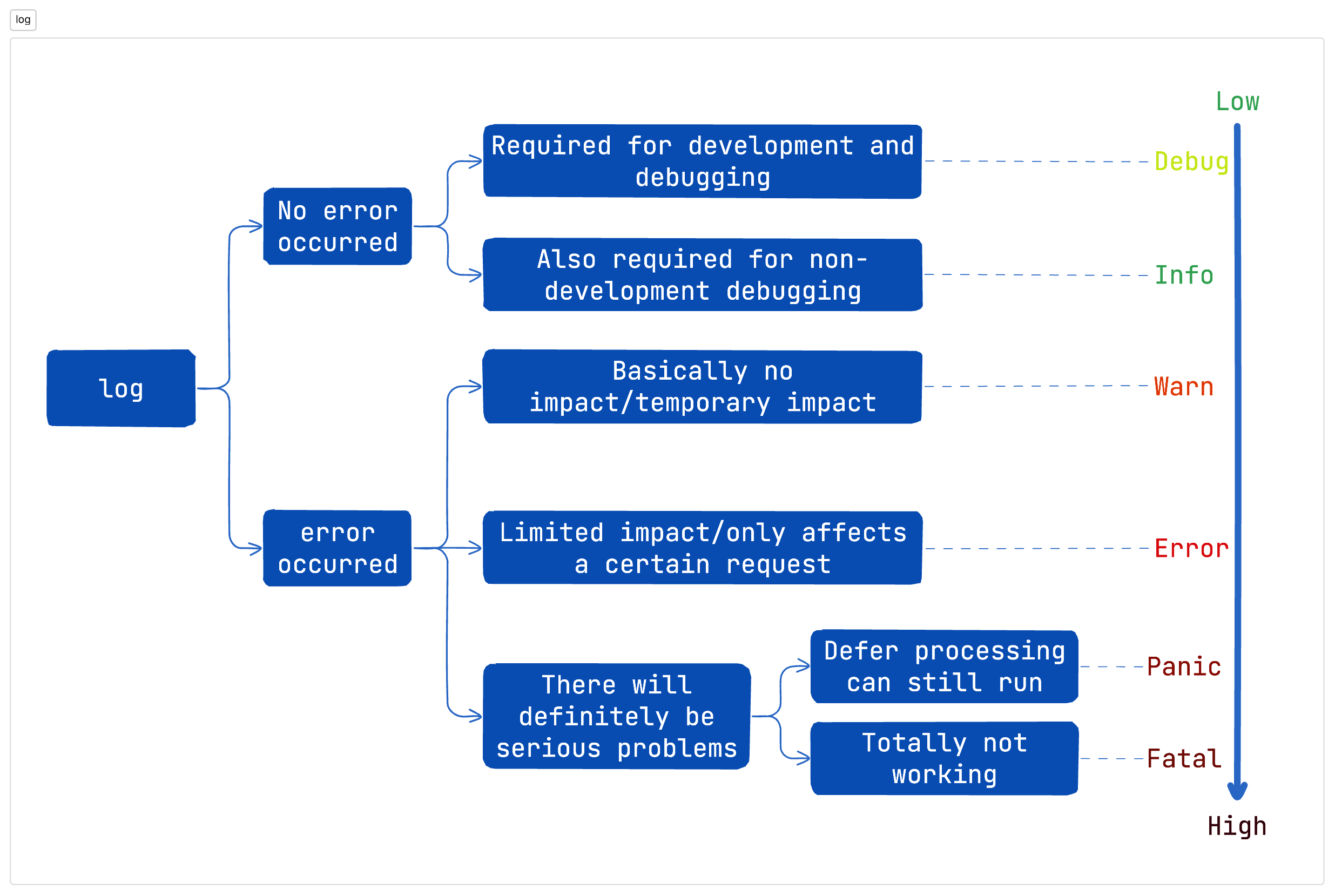
Logs of different levels have different meanings and can achieve different functions.
- Debug level
In order to obtain enough information for debugging, a lot of logs are usually printed at the debug level. For example, the request body or response body of the entire HTTP request can be printed.
The Debug level needs to print a lot of logs, which will seriously drag down the performance of the program. In addition, the Debug level logs are mainly for better debugging during the development and testing phase, and most of them are log information that does not affect the existing network business. Therefore, for Debug level logs, we must disable them when the service is launched. Otherwise, the hard disk space may be quickly used up due to a large number of logs, causing service downtime, and may also affect the performance of the service and product experience.
Logs at this level can be output at will. Any logs that you think will be helpful for debugging during the development and testing phases can be printed at this level.
- Info level
Info-level logs can record some useful information for future operational analysis, so the Info-level logs are not as many as possible, nor as few as possible. The main goal should be to meet the needs. Some key logs can be recorded at the Info level, but if the log volume is large and the output frequency is too high, consider recording at the Debug level.
The log level of the current network is generally Info level. In order to prevent the log file from occupying the entire disk space, when recording logs, be careful to avoid generating too many Info level logs. For example, in a for loop, use Info level logs with caution.
- Warn level
Some warning logs can be recorded at the Warn level. Warn-level logs often indicate that the program runs abnormally and does not meet expectations, but does not affect the continued operation of the program, or temporarily affects the program but will recover later. You need to pay attention to logs like these. Warn is more of a business-level warning log.
- Error level
Error-level logs tell us that program execution errors occur, and these errors will definitely affect the execution results of the program, such as request failures, resource creation failures, etc. It is necessary to record the logs of each error to prevent these errors from being ignored during future troubleshooting. Most errors can be classified as Error-level.
- Panic level
Panic-level logs are rarely used in actual development. They are usually only used when an error stack is needed or when defer is used to handle errors because the program does not want to exit due to a serious error.
- Fatal level
Fatal is the highest level of log. This level of log indicates that the problem is very serious, so serious that the program cannot continue to run. It is usually a system-level error. It is rarely used in development unless we think that the entire program cannot continue to run when an error occurs.
How to record log content?
- When recording logs, do not output sensitive information such as passwords, keys, etc.
- To facilitate debugging, some temporary logs are usually recorded at the Debug level. These log contents can start with some special characters, such as
log.Debugf("XXXXXXXXXXXX-1:Input key was: %s", setKeyName). In this way, after debugging is completed, you can find these temporary logs by searching for the XXXXXXXXXXXX string and delete them before committing. - The log content should start with a lowercase letter and end with a period (.), for example,
log.Info("update user function called."). - To improve performance, use explicit types when possible, for example
log.Warnf("init datastore: %s", err.Error()) instead of log.Warnf("init datastore: %v", err). - As needed, the log should preferably contain two pieces of information. One is the request ID, which is a unique ID for each request. It is convenient to filter out the log of a certain request from the massive logs. The request ID can be placed in the general log field of the request. The other is the user and behavior, which is used to identify who did what.
- Do not log at the wrong log level. For example, in project development, you will often find that some colleagues print normal log information at the Error level and print error log information at the Info level.
Best Practices
- When developing and debugging, or troubleshooting live network problems, don’t forget one thing: optimize log printing according to the troubleshooting process. A good log may not be written in one go, and can be continuously optimized during actual development and testing, as well as when locating problems on the live network. But this requires you to pay attention to logs, rather than just treating logs as a way to record information, or even not knowing why an Info log is printed.
- Print logs in moderation, avoid printing useless logs, and do not miss critical log information. The best information is that the problem can be located based on these critical logs alone.
- Supports dynamic log output to facilitate online problem location.
- Always record logs in local files: By recording logs in local files, they can be decoupled from the centralized log platform, so that when the network is unavailable or the centralized log platform fails, logs can still be recorded normally.
- Centralized log storage and processing: Because an application may contain multiple services and a service may contain multiple instances, it is best to store these logs on the same log platform, such as Elasticsearch, for the convenience of viewing logs.
- Structured logging: Add some default common fields to each line of log to facilitate log query and analysis.
- Support RequestID: Use RequestID to concatenate all logs of a request, which may be distributed in different components and different machines. Supporting RequestID can greatly improve the efficiency of troubleshooting and reduce the difficulty of troubleshooting. In some large distributed systems, troubleshooting without RequestID is simply a disaster.
- Support dynamic switch of debug log: To locate some hidden problems, more information may be needed, and debug log may need to be printed at this time. However, the log level of the existing network is set to Info level. In order to obtain debug log, we may change the log level to Debug level and restart the service. After locating the problem, change the log level to Info level and restart the service. This method is not only troublesome but also may affect the existing network business. The best way is to dynamically control whether debug log is turned on for a request through parameters such as debug=true in the request.