- 如果要做一个数据库路由,都需要做什么技术点?
- 一个数据库路由设计要包括哪些技术知识点呢?
Table of contents
需求分析
如果要做一个数据库路由,都需要做什么技术点?
首先我们要知道为什么要用分库分表,其实就是由于业务体量较大,数据增长较快,所以需要把用户数据拆分到不同的库表中去,减轻数据库压力。 分库分表操作主要有垂直拆分和水平拆分:
- 垂直拆分:指按照业务将表进行分类,分布到不同的数据库上,这样也就将数据的压力分担到不同的库上面。最终一个数据库由很多表的构成,每个表对应着不同的业务,也就是专库专用。
- 水平拆分:如果垂直拆分后遇到单机瓶颈,可以使用水平拆分。相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而本章节需要实现的水平拆分,是把同一个表拆到不同的数据库中。如:user_001、user_002
水平拆分的路由设计,如图:
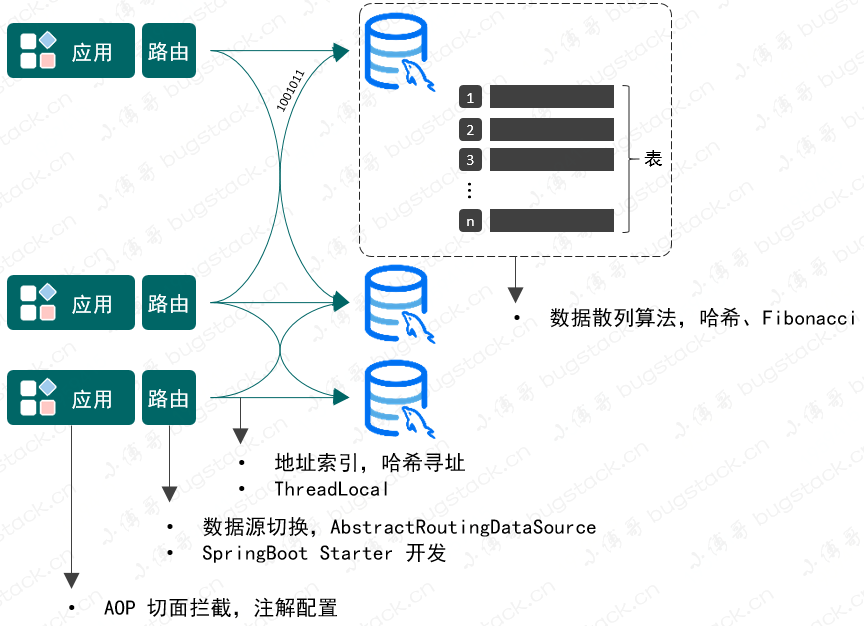
那么,这样的一个数据库路由设计要包括哪些技术知识点呢?
- 是关于 AOP 切面拦截的使用,这是因为需要给使用数据库路由的方法做上标记,便于处理分库分表逻辑。
- 数据源的切换操作,既然有分库那么就会涉及在多个数据源间进行链接切换,以便把数据分配给不同的数据库。
- 数据库表寻址操作,一条数据分配到哪个数据库,哪张表,都需要进行索引计算。在方法调用的过程中最终通过 ThreadLocal 记录。
- 为了能让数据均匀的分配到不同的库表中去,还需要考虑如何进行数据散列的操作,不能分库分表后,让数据都集中在某个库的某个表,这样就失去了分库分表的意义。
综上,可以看到在数据库和表的数据结构下完成数据存放,我需要用到的技术包括:AOP、数据源切换、散列算法、哈希寻址、ThreadLocal以及SpringBoot的Starter开发方式等技术。
设计实现
定义路由注解
- 定义
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface DBRouter {
String key() default "";
}- 使用
@Mapper
public interface IUserDao {
@DBRouter(key = "userId")
User queryUserInfoByUserId(User req);
@DBRouter(key = "userId")
void insertUser(User req);
}- 首先我们需要自定义一个注解,用于放置在需要被数据库路由的方法上。
- 它的使用方式是通过方法配置注解,就可以被我们指定的 AOP 切面进行拦截,拦截后进行相应的数据库路由计算和判断,并切换到相应的操作数据源上。
解析路由配置
# 多数据源路由配置
mini-db-router:
jdbc:
datasource:
dbCount: 2
tbCount: 4
default: db00
routerKey: uId
list: db01,db02
db00:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/lottery?useUnicode=true
username: root
password:
db01:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/lottery_01?useUnicode=true
username: root
password:
db02:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/lottery_02?useUnicode=true
username: root
password:- 以上就是我们实现完数据库路由组件后的一个数据源配置,在分库分表下的数据源使用中,都需要支持多数据源的信息配置,这样才能满足不同需求的扩展。
- 对于这种自定义较大的信息配置,就需要使用到 org.springframework.context.EnvironmentAware 接口,来获取配置文件并提取需要的配置信息。
数据源配置提取
@Override
public void setEnvironment(Environment environment) {
String prefix = "router.jdbc.datasource.";
dbCount = Integer.valueOf(environment.getProperty(prefix + "dbCount"));
tbCount = Integer.valueOf(environment.getProperty(prefix + "tbCount"));
String dataSources = environment.getProperty(prefix + "list");
for (String dbInfo : dataSources.split(",")) {
Map<String, Object> dataSourceProps = PropertyUtil.handle(environment, prefix + dbInfo, Map.class);
dataSourceMap.put(dbInfo, dataSourceProps);
}
}- prefix,是数据源配置的开头信息,你可以自定义需要的开头内容。
- dbCount、tbCount、dataSources、dataSourceProps,都是对配置信息的提取,并存放到 dataSourceMap 中便于后续使用。
数据源切换
在结合 SpringBoot 开发的 Starter 中,需要提供一个 DataSource 的实例化对象,那么这个对象我们就放在 DataSourceAutoConfig 来实现,并且这里提供的数据源是可以动态变换的,也就是支持动态切换数据源。
- 创建数据源
Bean
public DataSource dataSource() {
// 创建数据源
Map<Object, Object> targetDataSources = new HashMap<>();
for (String dbInfo : dataSourceMap.keySet()) {
Map<String, Object> objMap = dataSourceMap.get(dbInfo);
targetDataSources.put(dbInfo, new DriverManagerDataSource(objMap.get("url").toString(), objMap.get("username").toString(), objMap.get("password").toString()));
}
// 设置数据源
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(new DriverManagerDataSource(defaultDataSourceConfig.get("url").toString(), defaultDataSourceConfig.get("username").toString(), defaultDataSourceConfig.get("password").toString()));
return dynamicDataSource;
}
- 这里是一个简化的创建案例,把基于从配置信息中读取到的数据源信息,进行实例化创建。
- 数据源创建完成后存放到 DynamicDataSource 中,它是一个继承了 AbstractRoutingDataSource 的实现类,这个类里可以存放和读取相应的具体调用的数据源信息。
切面拦截
在 AOP 的切面拦截中需要完成;数据库路由计算、扰动函数加强散列、计算库表索引、设置到 ThreadLocal 传递数据源,整体案例代码如下:
@Around("aopPoint() && @annotation(dbRouter)")
public Object doRouter(ProceedingJoinPoint jp, DBRouter dbRouter) throws Throwable {
String dbKey = dbRouter.key();
if (StringUtils.isBlank(dbKey)) throw new RuntimeException("annotation DBRouter key is null!");
// 计算路由
String dbKeyAttr = getAttrValue(dbKey, jp.getArgs());
int size = dbRouterConfig.getDbCount() * dbRouterConfig.getTbCount();
// 扰动函数
int idx = (size - 1) & (dbKeyAttr.hashCode() ^ (dbKeyAttr.hashCode() >>> 16));
// 库表索引
int dbIdx = idx / dbRouterConfig.getTbCount() + 1;
int tbIdx = idx - dbRouterConfig.getTbCount() * (dbIdx - 1);
// 设置到 ThreadLocal
DBContextHolder.setDBKey(String.format("%02d", dbIdx));
DBContextHolder.setTBKey(String.format("%02d", tbIdx));
logger.info("数据库路由 method:{} dbIdx:{} tbIdx:{}", getMethod(jp).getName(), dbIdx, tbIdx);
// 返回结果
try {
return jp.proceed();
} finally {
DBContextHolder.clearDBKey();
DBContextHolder.clearTBKey();
}
}
- 简化的核心逻辑实现代码如上,首先我们提取了库表乘积的数量,把它当成 HashMap 一样的长度进行使用。
- 接下来使用和 HashMap 一样的扰动函数逻辑,让数据分散的更加散列。
- 当计算完总长度上的一个索引位置后,还需要把这个位置折算到库表中,看看总体长度的索引因为落到哪个库哪个表。
- 最后是把这个计算的索引信息存放到 ThreadLocal 中,用于传递在方法调用过程中可以提取到索引信息。
Mybatis 拦截器处理分表
- 最开始考虑直接在Mybatis对应的表 INSERT INTO user_strategy_export_${tbIdx} 添加字段的方式处理分表。但这样看上去并不优雅,不过也并不排除这种使用方式,仍然是可以使用的。
- 那么我们可以基于 Mybatis 拦截器进行处理,通过拦截 SQL 语句动态修改添加分表信息,再设置回 Mybatis 执行 SQL 中。
- 此外再完善一些分库分表路由的操作,比如配置默认的分库分表字段以及单字段入参时默认取此字段作为路由字段。
@Intercepts({@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})})
public class DynamicMybatisPlugin implements Interceptor {
private Pattern pattern = Pattern.compile("(from|into|update)[\\s]{1,}(\\w{1,})", Pattern.CASE_INSENSITIVE);
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 获取StatementHandler
StatementHandler statementHandler = (StatementHandler) invocation.getTarget();
MetaObject metaObject = MetaObject.forObject(statementHandler, SystemMetaObject.DEFAULT_OBJECT_FACTORY, SystemMetaObject.DEFAULT_OBJECT_WRAPPER_FACTORY, new DefaultReflectorFactory());
MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
// 获取自定义注解判断是否进行分表操作
String id = mappedStatement.getId();
String className = id.substring(0, id.lastIndexOf("."));
Class<?> clazz = Class.forName(className);
DBRouterStrategy dbRouterStrategy = clazz.getAnnotation(DBRouterStrategy.class);
if (null == dbRouterStrategy || !dbRouterStrategy.splitTable()){
return invocation.proceed();
}
// 获取SQL
BoundSql boundSql = statementHandler.getBoundSql();
String sql = boundSql.getSql();
// 替换SQL表名 USER 为 USER_03
Matcher matcher = pattern.matcher(sql);
String tableName = null;
if (matcher.find()) {
tableName = matcher.group().trim();
}
assert null != tableName;
String replaceSql = matcher.replaceAll(tableName + "_" + DBContextHolder.getTBKey());
// 通过反射修改SQL语句
Field field = boundSql.getClass().getDeclaredField("sql");
field.setAccessible(true);
field.set(boundSql, replaceSql);
return invocation.proceed();
}
}- 实现 Interceptor 接口的 intercept 方法,获取StatementHandler、通过自定义注解判断是否进行分表操作、获取SQL并替换SQL表名 USER 为 USER_03、最后通过反射修改SQL语句
- 此处会用到正则表达式拦截出匹配的sql,(from|into|update)[\s]{1,}(\w{1,})
事物处理
为了避免多个表数据源进行切换,事物失效,进行了设计。
@Bean
public TransactionTemplate transactionTemplate(DataSource dataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dataSource);
TransactionTemplate transactionTemplate = new TransactionTemplate();
transactionTemplate.setTransactionManager(dataSourceTransactionManager);
transactionTemplate.setPropagationBehaviorName("PROPAGATION_REQUIRED");
return transactionTemplate;
}使用方法:手动显示处理事物即可。
public Result recordDrawOrder(DrawOrderVO drawOrder){
try {
dbRouter.doRouter(drawOrder.getuId());
return transactionTemplate.execute(status -> {
try {
//TODO 更新表一
//TODO 更新表二
}catch(Exception e){
status.setRollbackOnly();
// 其他操作
}
});
} finally{
dbRouter.clear();
}
}